A linear regression model is arguably the simplest model we can make about the world around us. Despite being simple, they are very successful at making predictions. In physics for example, laws that are linear are plenty. How much force $F$ a spring pull back as you stretch it by an amount $\Delta x$? Hooke’s law tells us the relationship is linear: $F = -k \Delta x$. In everyday life we expect cause and effect to have a linear relationship. It makes sense to us that a house should have a constant price to area ratio given that other factors like location are fixed. Linear regression models are easy to understand (there are many caveats to this statement, we come back to this later) which make them appealing for predictions.
In this blog post I discuss:
- What is a linear regression model, and where the name comes from
- Linear regression as a statistical model
- The exact solution for the model parameters
- Limitations of the linear model
Best fitting as an algorithm
Let’s take Hooke’s law as a concrete example. We are interested in how much a weight attached to a spring stretches it. Usually the relationship is stated with the weight being the independent variable, so we ask, how much weight can the spring support if we stretch it by some amount? In general we can write $W = f(x)$, where $W$ is the weight, and $x$ is the position of that weight. How do we figure out this relationship? We need to start by collecting data, i.e. make an experiment. We make a spring, clamp one end, and the other end hang vertically. Next, we get a set of weights, and start attaching them to the hanging end of the spring. With every added weight the spring is stretched by a certain amount which we can record by attaching a ruler next to the spring.
Now we make a plot of the $W$ against $x$. We find that the plot looks linear, that is we can (almost) connect all of our data points using a straight line. We make the assumption that \(W = \theta_0 + \theta_1 x,\) and try to find the best $\theta_0$ and $\theta_1$ so that we best fit our measurements.
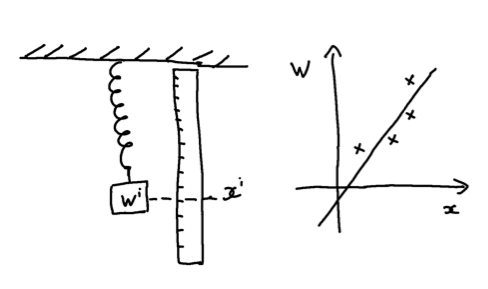
How do we best fit the data? One way is to graphically fit a line by eye. On a physical piece of paper, plot the data, and then with a ruler and pen draw a line such that there is roughly equal number of data points above and below the line. This may be the simplest form of linear regression, and if you have done this exercise in high-school, you have implemented linear regression already.
You might be thinking, if the points are linear, can’t we connect two points by a straight line and then we should have all other points automatically fall onto that line? The reason this doesn’t work is that even in this simple example the data is noisy. There are some unavoidable errors associated with our measurements. For one, we are limited by the accuracy of the ruler, for example. Also the data is collected by a human, and maybe measurements were affected by the parallax effect. Might be that half-way throughout the experiment someone knocked the ruler out of place, and despite your best efforts to put it in the same exact location it wasn’t at exactly the same location. There might also be errors associated with the value of the weights. Maybe one of the weights got a little chip, and we are also limited by the accuracy of the machining process that made the weights. Point being, there are many sources of errors when collecting data in the real world. The errors move the points away from the supposedly true straight line in random directions. Thus connecting two points of data is not a good strategy to obtaining the best-fit line.
My guess is that even high-schoolers don’t do linear fitting by hand anymore. Excel would give you the line of best fit if you feed it the data in no time. How does it figure out the best $\theta_0$ and $\theta_1$? To solve a problem on a computer, we need to write an algorithm. As is usually the case, we can’t formulate the eyeballing method to the computer. Instead, we define a function that describes how far the prediction of our model is from the true data, and then minimize One function that achieves this goal is
\[\mathcal L(\theta_0, \theta_1) = \frac{1}{2N} \sum_i (\theta_0+ \theta_1 x^i - W^i)^2\]where $W^i$ and $x^i$ are the measured weights and positions respectively and $N$ is the number of total measurements made. The further away the prediction of our model, $\theta_0+ \theta_1 x^i$, is from the observed data the larger the loss function. This loss function is called the mean-squared error (MSE). Our job is to find the parameters that give us the smallest possible loss. Formally this is written as
\[\boldsymbol \theta = \underset{\boldsymbol \theta}{\text{argmin}} \ \mathcal L(\boldsymbol \theta)\]which reads that the optimal $\boldsymbol \theta = (\theta_0, \theta_1)$ are obtained by finding the arguments of the function $\mathcal L(\boldsymbol \theta)$ that minimize it. We will get to how to find these optimal parameters later on.
Linear regression can be used in many contexts. In our spring example, we only had one “feature” that affected the weight attached to the spring, which is the position of the weight. However, in general we might want to consider more than one feature that can have an effect on the output of the model. The canonical example, which I believe was popularized by Andrew Ng (see lecture notes) is predicting housing prices. There are multiple factors that go into how much a house cost, like area, number of rooms, location, when it was built, etc.
In general, the linear model takes the following form x
\[y_{\boldsymbol \theta}(\boldsymbol x) = \sum_{\alpha=0}^{n} \theta_\alpha x_\alpha\]where $x_\alpha$ and $\theta_\alpha$ are the features and parameters of the model respectively. I will use bold symbols to indicate vectors in the feature space, for example $\boldsymbol x = [x_0, x_1, \dots ]$. Here the convention is that $x_0 = 1$ allowing for a constant term, i.e. the prediction of the model when all features are zero.
Here we encounter the first example showing how tricky understanding a model can be. What is the meaning of $\theta_0$ in the example of predicting house pricing? The price of a house with zero area, number of rooms, … You can already see how silly that sounds. While it is true that this is what the model would spit out when we input a data point with $x_\alpha = 0, \forall \ \alpha> 0$, saying that the meaning of $\theta_0$ is the price of a house with these features is a meaningless statement. There is no such house. I wanted to point this out. I’ll leave discussion about interpretability for another blog.
Linear regression model as a statistical model
Let’s get back to the loss function. Why not take absolute values, or powers of $4$ of the errors? One can derive the MSE loss function by looking at the linear regression model as a statistical model. We already mentioned how errors are unavoidable when collecting data. Thus in general we should expect
\[y_{\boldsymbol \theta}(\boldsymbol x) = \sum_{\alpha=0}^{n} \theta_\alpha x_\alpha + \epsilon\]where $\epsilon$ quantifies the errors we make. To know what is $\epsilon$, we need to have a model for the errors. The most natural, and common choice is to take the errors to follow a gaussian distribution. So rather than saying that given the features $x_\alpha$ our prediction is certainly $y_{\boldsymbol \theta}(\boldsymbol x)$, we have a probability distribution. We ask, given the features $x_\alpha$ what is the probability that we make a prediction $y$? This is written as $p(y|\boldsymbol x)$, and in the case of the normal distribution is given by
\[p(y|\boldsymbol x;\boldsymbol \theta) = \frac{1}{\mathcal N } e^{(y - \mu_{\boldsymbol \theta}(\boldsymbol x))^2/2\sigma^2}.\]Our linear model makes predictions about the mean of the normal distribution
\[\mu_{\boldsymbol \theta}(\boldsymbol x) = \sum_\alpha \theta_\alpha x_\alpha.\]In other words, the model makes predictions by giving its best guess of what the mean of the distribution is. The data set is a list of $(y^i, \boldsymbol x^i)$, where $y^i$ is the effect we are trying to model, and $\boldsymbol x^i$ are the features that determine that effect. We denote the list of all $y^i$’s as $Y = [y^0, y^1 , \dots, y^{N-1} ]$ and the list of all $x^i$’s as $\boldsymbol X = [\boldsymbol x^0, \boldsymbol x^1, \dots, \boldsymbol x^{N-1}]$. In our notation, a bold symbol is a vector in the feature space, and a capital letter symbol is a list of the data. A bold capital letter means it is the data list of the features vectors. We can think of $\boldsymbol X$ as a matrix, the components of which are given by $\boldsymbol X_{i \alpha} = x^i_\alpha$.
The probability of $Y$ given $X$ is the product of all $p(y^i|\boldsymbol x^i;\boldsymbol \theta)$
\[p(Y|X; \boldsymbol \theta) = \prod_i p(y^i|\boldsymbol x^i;\boldsymbol \theta).\]When we view $p(Y|X; \boldsymbol \theta)$ as a function of the parameters $\boldsymbol \theta$, we call this function the likelihood of the parameters
\[L(\boldsymbol \theta) := p(Y|X; \boldsymbol \theta).\]I won’t get too much into a discussion of probability vs. likelihood. Maybe in another blog.
The best model parameters are those that maximize the likelihood $L(\boldsymbol \theta)$. We find the maximum likelihood by minimizing minus its log. The reason this works is because the log is a monotonic function. The reason this is a good idea is that it gives a simple expression to work with
\[-\log L (\boldsymbol \theta) = \frac{1}{2\sigma^2} \sum_i (y^i - \mu_{\boldsymbol \theta } (\boldsymbol x^i))^2 + \text{const.}\]We thus see that 1. Minimizing minus log of the likelihood is the same as maximizing the likelihood of the parameters, and that 2. Minimizing the minus log of the likelihood is the same as minimizing the MSE between $y^i$ and the mean of the normal distribution, which is the model prediction.
Where does the name regression come from?
This part is probably not important and you can skip if you want. However, the name regression always sounded weird to me. Why not call it linear fitting? According to the Wikipedia page on regression analysis, the name comes from the statistical phenomena of “regression to the mean”. Veritasium has a nice video explaining this concept. I’ll summarize here with a silly example. Suppose you roll a $1000$ dice. The mean of the numbers on the faces would be close to $3.5$. If we take the dice with faces showing $5$ and $6$ which have an average of about $5.5$ and roll them again, then the mean of these dice would regress back from $5.5$ to something much closer to mean of the original distribution which is $3.5$. Basically there is nothing inherently special about the dice that was showing high numbers on the first run, and if we roll them again they perform like all other dice. The same effect can show up in more subtle situations. I’ll refer to the Veritasium video for an interesting example.
As we alluded to already, when collecting our data, we are sampling from some probability distribution (because of the errors associated with measurements), the mean of which have a linear relationship with the model features. So are we predicting the mean the data is regressing to? I am not convinced this is a good name, but okay. Let me know if you have a better explanation.
Normal equation for the parameters
A nice feature of the linear model is that there is a closed form for the optimal parameters. In matrix form, the loss function takes the following form
\[\mathcal L(\boldsymbol \theta) = \frac{1}{2N}(Y - \boldsymbol X \boldsymbol \theta)^T (Y - \boldsymbol X\boldsymbol \theta) = \frac{1}{N}[ Y^T Y - \boldsymbol \theta^T X^T Y - Y^T X\boldsymbol \theta + \boldsymbol \theta^T X^T X \boldsymbol \theta]. \tag{1}\]To find the minimum of $\mathcal L(\boldsymbol \theta)$ we need to set the derivatives with respect to all parameters to zero $\partial \mathcal L (\boldsymbol \theta) / \partial \theta_\alpha = 0\ \forall \ \alpha$. For ease of notation, we define
\[\frac{\partial \mathcal L }{\partial \boldsymbol \theta} = \begin{bmatrix} \frac{\partial \mathcal L }{\partial \theta_0 }\\ \frac{\partial \mathcal L }{\partial \theta_1} \\ \vdots \\ \frac{\partial \mathcal L }{\partial \theta_n} \end{bmatrix}\]When taking the derivative of $(1)$, with respect to $\theta$ the first term doesn’t depend on $\theta$, the second and third terms are equal, and so are the derivatives
\[\frac{\partial}{\partial \boldsymbol \theta} Y^TX \boldsymbol \theta = \frac{\partial}{\partial \boldsymbol \theta} \boldsymbol \theta^T \boldsymbol X^T Y = X^T Y.\]The derivative of the quadratic term (the last term) in Eq. (1) is somewhat less obvious, at least for me. The way I remind myself of how to do it is by adding a small term to the variable we are taking the derivative for and collect the linear terms
\[\boldsymbol \theta^T X^T X \boldsymbol \theta \rightarrow (\boldsymbol \theta^T + \delta \boldsymbol \theta^T) X^T X (\boldsymbol \theta + \delta \boldsymbol \theta)\]collecting the first order terms in $\delta \boldsymbol \theta$ we find that the change we make is
\[\delta (\boldsymbol \theta^T X^T X \boldsymbol \theta ) = \delta \boldsymbol \theta^T X^T X + X^T X \delta \theta = 2 \delta \boldsymbol \theta^T X^T X\]and thus in the limit of $\delta \boldsymbol \theta \rightarrow 0 $
\[\frac{\partial}{\partial \boldsymbol \theta} \boldsymbol \theta^T X^T X \boldsymbol \theta = 2 X^T X.\]Putting everything together we have
\[\frac{\partial \mathcal L }{\partial \boldsymbol \theta} = \frac{1}{N} [-X^T Y + X^T X \boldsymbol \theta]\]Setting the derivative to zero we get an equation for the optimal parameters
\[\boldsymbol \theta = (\boldsymbol X^T \boldsymbol X)^{-1} \boldsymbol X^T Y.\]There might be some subtleties with inverting the matrix $\boldsymbol X^T \boldsymbol X $, but that is outside the scope of this blog for now. I just wanted to highlight that there exists a closed form solution.
Limitations of the linear model
It comes as no surprise that a lot of our world is not linear, making the limitations of the linear model pretty obvious. However, one can easily expand its scope by feature engineering. Suppose you want to build a linear model to predict the range an electric car has on a single charge. To make things simple, let’s assume highway driving, so no stopping and starting. You know that the range should depend on the speed you are driving with. You might build the model for the range with a linear term $\beta_v v$ where $v$ is the speed you are driving with. A negative $\beta_v$ would indeed give us the correct behavior of decreasing range with increasing velocity. However such model is not accurate, since the relationship between the range and velocity is inherently non-linear. If we have a bit of knowledge about drag forces we might add the following term to the model $\tilde \beta_v \frac{1}{v^2}$. Such term should improve the accuracy of the model since it includes the correct scaling of drag forces with velocity. Including this term in the model is what is known as feature engineering. In this example, we had a good idea of what is the correct feature to include. In more complex situations we might not know. Going back to the housing pricing example, we might expect that at some point, the bigger the areas of a house the price would shoot upwards not in a linear fashion, maybe because we are now in a different category of real-estate, like moving from the realms of apartments to houses or form houses to mansions.
Another limitation of the linear model is that it ignore correlation between features. In the housing prices example, we should expect location and area to be correlated. A slightly bigger house in a desirable location might cost a lot more than a slightly bigger house in a less desirable location, for example. A model with terms $\theta_{\text{area} } (\text{area} ) + \theta_{\text{location} } (\text{location} ) $ can never capture this effect.
One can add an interaction terms to the linear model to capture such effects. For example we can add $\theta_{\text{int}} (\text{area}) (\text{location})$. The obvious limitation is that we are not sure what is the correct form of the interaction and we can only guess in many situations. The other drawback is now terms in the model are not independent, and this makes understanding the model a lot more opaque. What is the meaning of the $\theta_{\text{area}}$ when we also have $\theta_{\text{int}}$? How much the price would change if we changed the area with other features being equal is suddenly a meaningless statement.
Linear models are very capable for what they are. They are easy to implement, and they seem to perform well in many cases. If we can also limit the model to small number of features, then their predictions are easy to understand by a human. All these factors make them very popular and appealing to use. They are probably a good starting point if we are tackling a problem we don’t have much experience with.